
Learning to Learn: How Verifiable Rewards Drive AI’s Latest Leap
Recent advancements in AI model development have revealed a fascinating shift in how these systems learn and improve. Just weeks ago, OpenAI announced that their unreleased O3 model achieved a remarkable milestone – scoring in the 99.8th percentile globally on Codeforces (a competitive programming platform where developers solve complex algorithmic problems under time pressure), placing it among the world’s top 175 competitive programmers. This achievement, while impressive on its own, points to a broader transformation in how AI systems are trained to tackle complex problems.
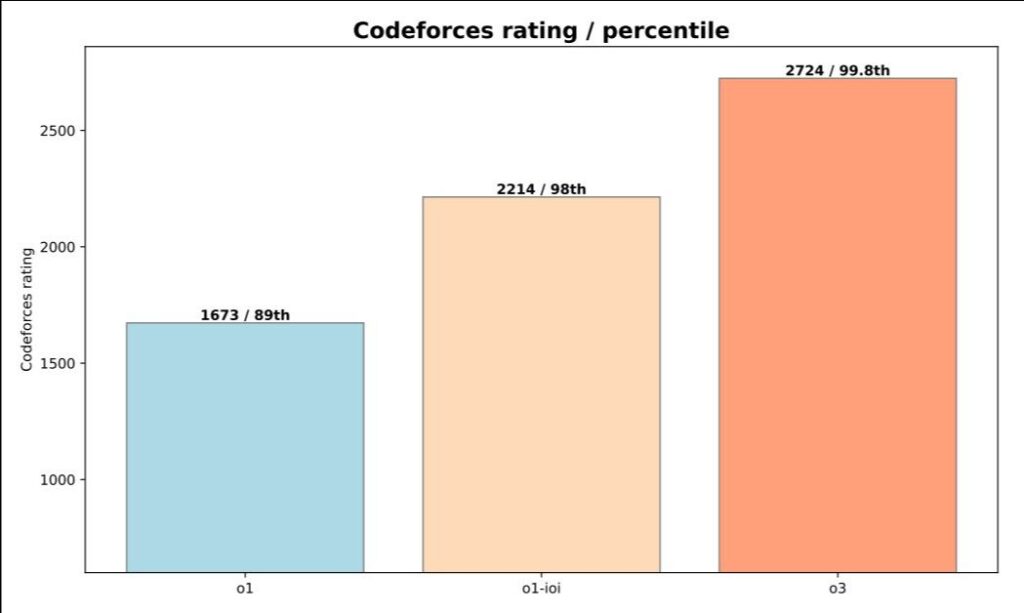
Performance of Various Reasoning Models on the Codeforces benchmark
What’s particularly interesting isn’t just the achievement itself, but how it was accomplished. The key lies in a new training approach called Reinforcement Learning with Verifiable Rewards (RLVR), recently detailed in DeepSeek’s technical publications. This method transforms problems with definitive solutions into learning opportunities for AI models, similar to how chess engines learn by playing millions of games with definitive wins and losses. By focusing on tasks where success can be clearly verified – like whether code compiles and passes test cases or whether a mathematical solution is correct – models can learn to develop sophisticated problem-solving strategies through trial and error.
The practical implications of this advancement were demonstrated in OpenAI’s new SWE-Lancer benchmark, which evaluates AI models on real-world software engineering tasks from Upwork. The benchmark includes over 1,400 tasks valued at $1 million in total, ranging from simple bug fixes to complex feature implementations. Current generation models are already capable of solving problems worth hundreds of thousands of dollars; with the current rate of improvement, it will be interesting to see how the next generation of models perform on benchmarks like these.
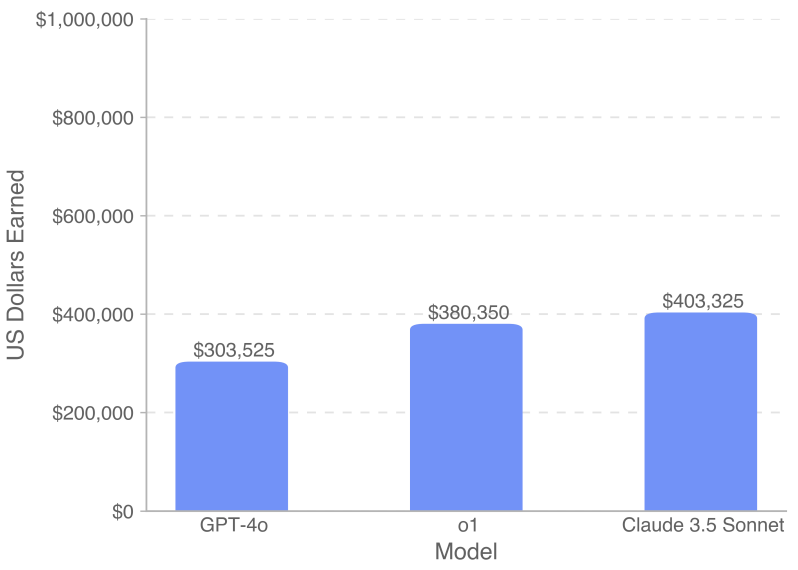
Total payouts earned by various models on the SWE-Lancer benchmark
What makes this development particularly significant is its potential to expand beyond coding. The same principles that allow AI to improve at programming tasks could theoretically apply to any domain with clear right and wrong answers – from physics and chemistry to medical diagnostics. Early signs of this generalization are already emerging, with models trained using RLVR on mathematical reasoning showing improved performance across various STEM-related tasks. One measure of this is the GPQA Diamond benchmark, which measures models’ ability to answer PhD-level STEM questions.
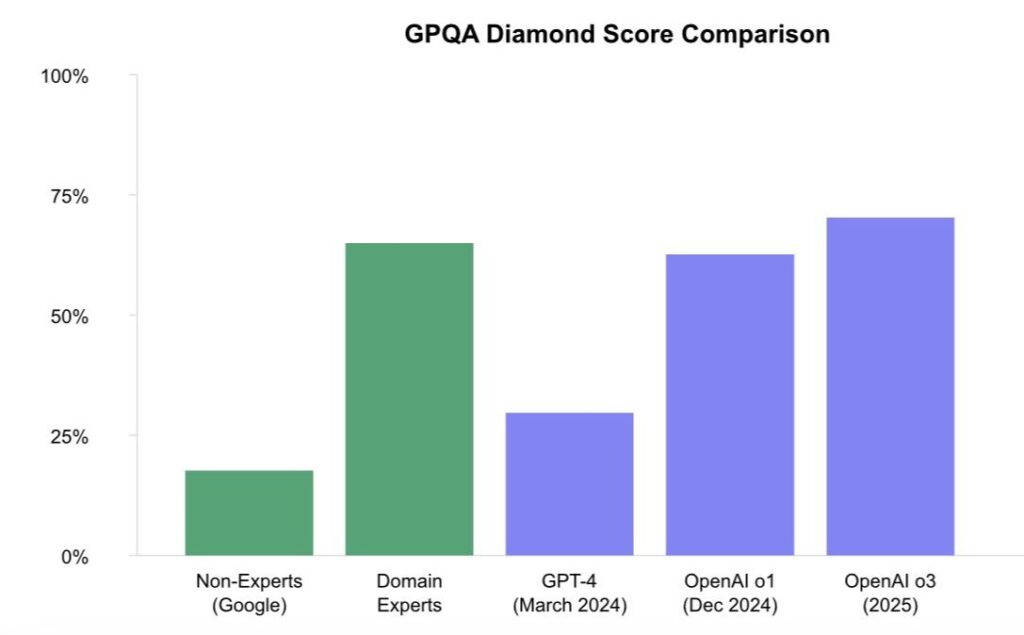
GPQA Diamond Scores: Comparing model performance against human experts on PhD-level STEM questions. Recent models are approaching expert-level performance across all domains.
For healthcare, this trend suggests we might see similar accelerated improvements in areas where outcomes can be clearly verified – from radiology readings to laboratory test interpretations. However, it’s crucial to note that unlike programming problems, medical applications require extensive validation and careful consideration of edge cases before deployment. The challenge of applying these techniques to more nuanced medical decisions – where the “right” answer isn’t always clear-cut – remains an open question.
We’re witnessing the emergence of a new paradigm in AI development – one that could dramatically accelerate progress in domains with verifiable outcomes. While the immediate impacts are most visible in technical fields like programming, the implications for healthcare and other scientific domains could be profound. As these systems continue to evolve, the key challenge will be ensuring their reliability and safety in high-stakes applications.



